自然语言处理--神经网络与文本应用
这章内容里非常多的数学公式,不过我个人觉得完全没必要记,一方面是许多都是我们之前的老朋友,另一方面神经网络的结构就像是这些公式可视化结果。学到这里笔者不得不感叹一下,虽然NLP的数学计算不少,但是真到写程序的时候也就是调用一个库函数的事情,所以哪怕你数学底子不好也没关系,你只要记住一些结论,并且跟着
这章内容里非常多的数学公式,不过我个人觉得完全没必要记,一方面是许多都是我们之前的老朋友,另一方面神经网络的结构就像是这些公式可视化结果。学到这里笔者不得不感叹一下,虽然NLP的数学计算不少,但是真到写程序的时候也就是调用一个库函数的事情,所以哪怕你数学底子不好也没关系,你只要记住一些结论,并且跟着

按道理来讲这篇笔记该第一个发的,但是笔者整理笔记的时候觉得这章不重要就直接跳过了。这章的内容也确实不难,大部分内容也是了解即可,为数不多需要记的就是那几个常用的正则表达式和字符编辑距离的计算(话说这算法被出成动态规划算法题出现在各位的考试中的概率真不低)。总之要是你要是按笔者发布笔记的时间顺序阅读的
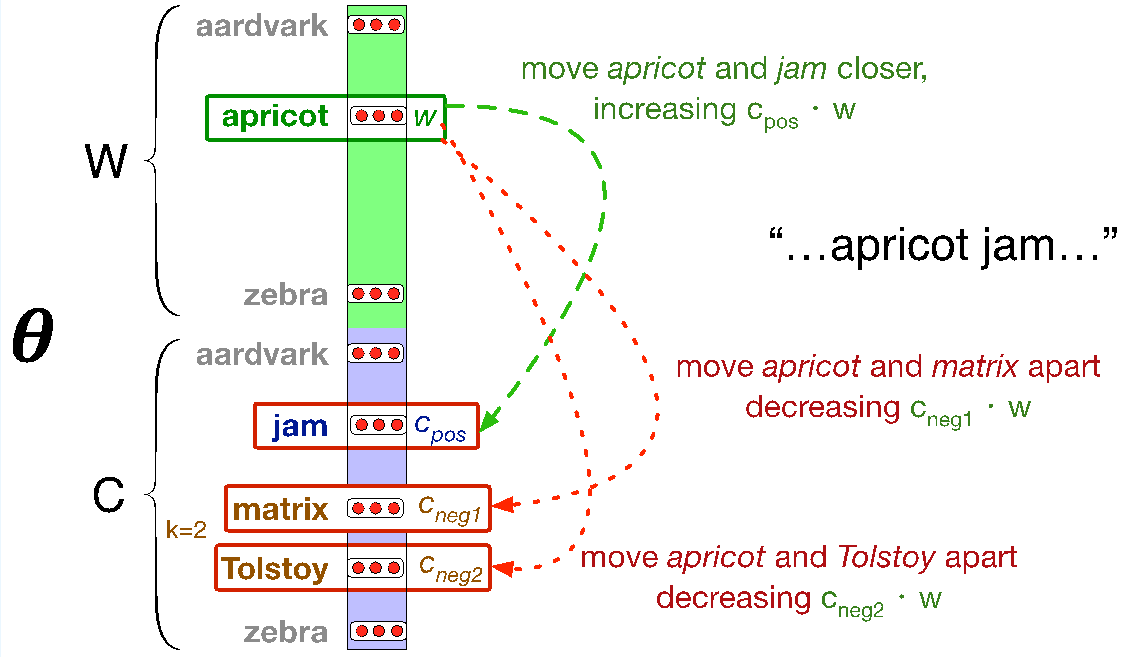
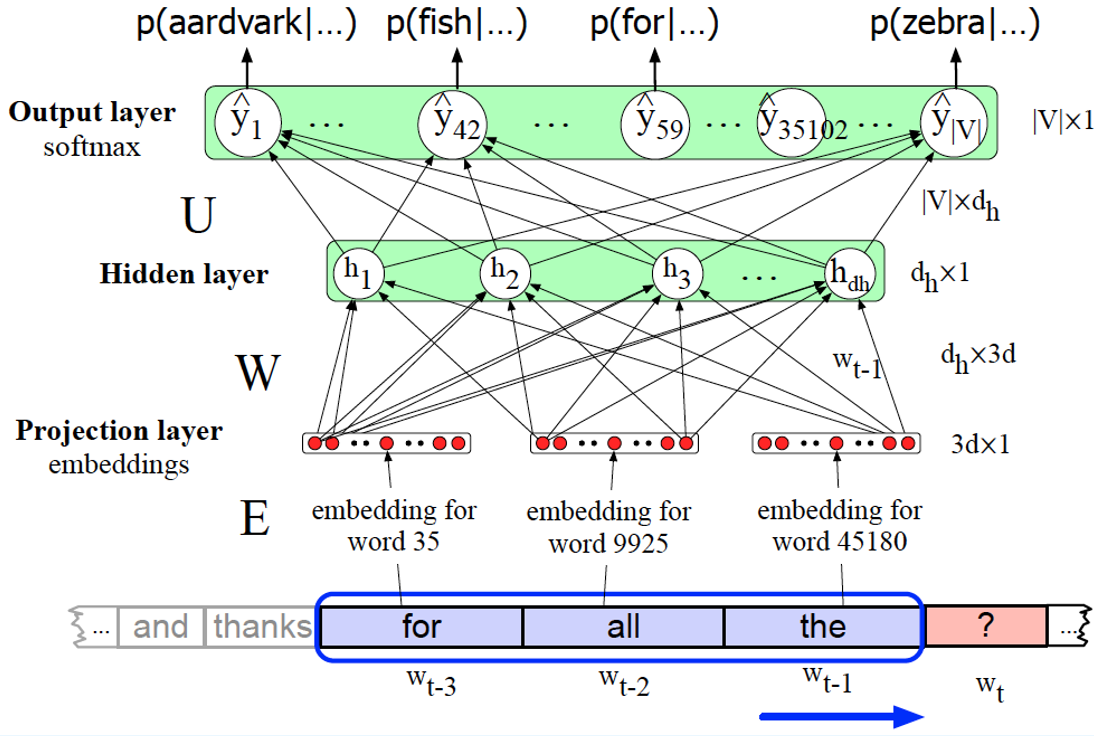
如果在这一节前你阅读过《自然语言处理--文本分类》,那应该对特征向量有印象,我们将一段文本转化为一段向量,维度i的值便是文本位置i上的单词的统计词频。同样的,我们也希望能把每个单词转化为向量,用于表示这个单词的词义,这就是我们常说的“词向量(Word embedding)“。我们按照某种规则,将词义
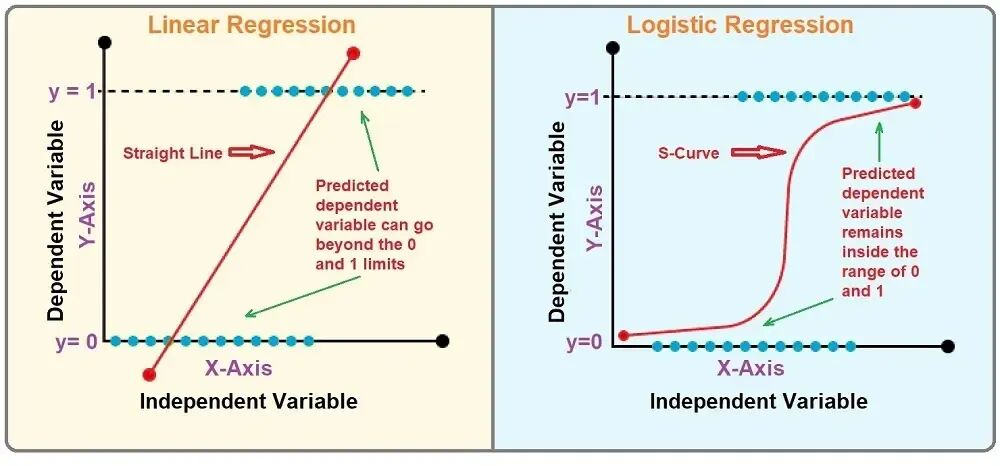
如果你接触过机器学习,那你就知道老师的实验课都会给你一堆数据,让你标注其中一些数据喂给模型让它自己学习,然后再丢给它一些未标注的数据来测试它的准确率。笔者最初对机器学习的认识就是这样--做分类。不过对于文本分类来说,我们有更好的方法。比如一本书里全是跟恋爱、青春有关的词,那它八成是本言情小说;一段影
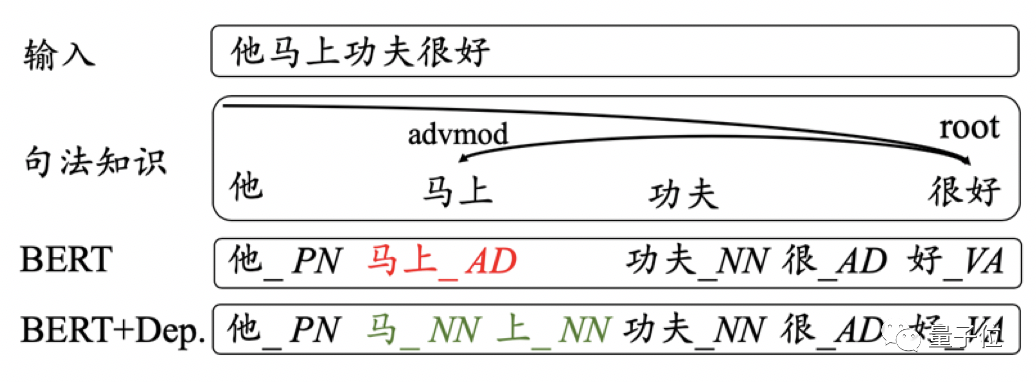
之前的笔记我们都是在讨论以英语为代表的西方自然语言如何在机器中处理的,实际上,机器在处理中文时更为困难,因为中文比西方语言更为复杂,比如英语两个词之间是有空格分开的,英语单词的词性比中文词更加明显,等等。在处理中文时,我们需要先将一句连续的话像英语那样拆分为各个单词,并为这些单词标注好词性,等等。我
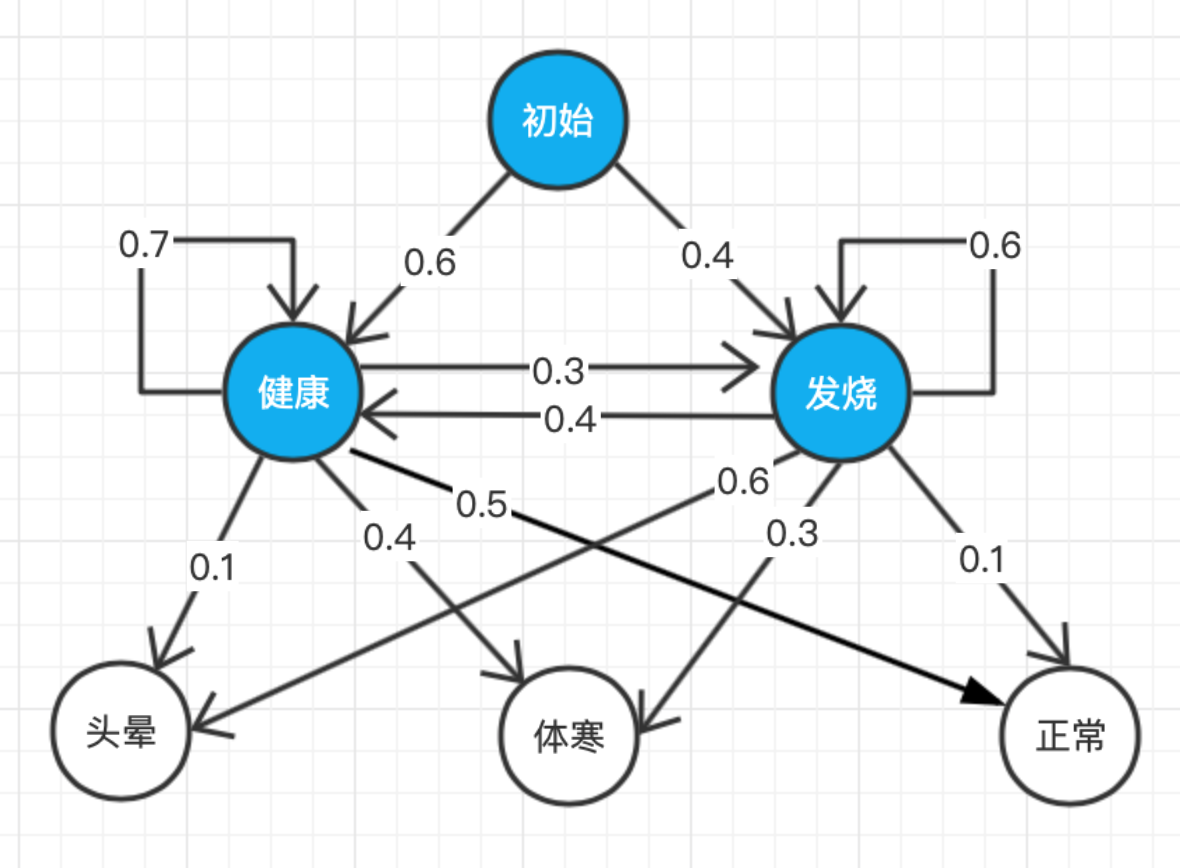
其实笔者感觉这一节的内容你或多或少在其他地方见过,因为HMM在应用太广了,并且在NLP其他章节中,HMM也是常客。不过要是这是你第一次接触HMM,那可能就很痛苦了。这节的笔记是笔者写的最痛苦的,因为公式非常多,理解起来有点吃力,幸运的是期末考试基本不会考这一节的复杂的公式推导与计算。另外,本节内容涉
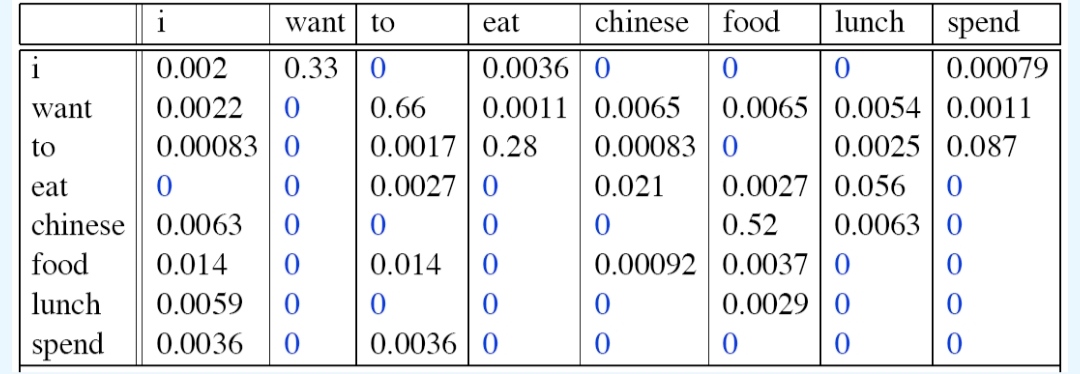
我感觉我写这个东西纯纯是在给自己期末复习...罢了,八成也是写给我自己看的,如果你刚好是那两成愿意看我整理这门课笔记的读者,那我要先说好:本文章由笔者在西北工业大学本科NLP(Natural Language Processing,自然语言处理)课程上课笔记整理而成,作为一门本科课程,这门课比科普向
One more time One more chance